大数据时代培训中心
7x24小时咨询热线
Severity: Warning
Message: preg_match(): No ending delimiter '^' found
Filename: controllers/School.php
Line Number: 699
Backtrace:
File: /data/web/collect_web/application/controllers/School.php
Line: 699
Function: preg_match
File: /data/web/collect_web/application/controllers/School.php
Line: 15
Function: get_real_ip
File: /data/web/collect_web/index.php
Line: 315
Function: require_once
7x24小时咨询热线

招生对象: 课程长度:4天/24小时 培训对象: 企业管理者、CIO、CTO、政府信息部门官员、项目(开发)经理、顾问;IT经理,IT顾问,IT支持专家;系统工程师、数据中心管理员、云计算管理员及想加入云计算队伍的您。 培训前提: 计算机相关专业;具备基本Linux系统管理经验;不需要事先掌握Hadoop相关知识。 认证证书: 通过考试可获得Cloudera Certified Administrator for Apache Hadoop (CCAH)。 培训目标: ?Hadoop 分布式文件系统和 MapReduce 工作原理 ?Hadoop 集群硬件配置规划 ?Hadoop 集群网络配置规划 ?Hadoop 集群配置及优化 ?如何配置NameNode HA ?任何配置NameNode Federation ?任何配置FairScheduler 为多用户共享 Hadoop 集群 ?任何为Hadoop 集群安装和实现基于 Kerberos 的安全性 ?维护和监测Hadoop 集群 ?使用Flume加载动态产生的文件以及使用Sqoop连接关系数据库进行数据导入导出 ?Hive、Pig 和 HBase 等 Hadoop 生态系统工具相关的系统管理工作 培训内容: ?介绍 ?ApacheHadoop 的应用案例 ?Hadoop 分布式文件系统 ?Hadoop 数据载入 ?MapReduce ?规划Hadoop 机群 ?Hadoop 安装和基本配置 ?安装配置Hive,Impala 和 Pig ?Hadoop 客户端 ?高级配置 ?Hadoop 安全 ?管理和调度作业 ?机群维护 ?机群监测和排错 ?结论 ?附录:Kerberos配置 ?附录:HDFSFederation 配置

招生对象: 课程长度:4天/24小时 培训对象: 企业管理者、CIO、CTO、政府信息部门官员、项目(开发)经理、顾问;IT经理,IT顾问,IT支持专家;系统工程师、数据中心管理员、云计算管理员及想加入云计算队伍的您。 培训前提: 具备编程经验的开发人员;熟悉面向对象高级编程语言,如Java;不需要事先掌握Hadoop相关知识。 课程目标: 通过考试可获得Cloudera Certified Developer for Apache Hadoop (CCDH) 证书。 培训目标: ?Hadoop 核心 ?HDFS 和MapReduce 工作原理 ?如何开发MapReduce 应用 ?如何单元测试 MapReduce 应用 ?如何使用MapReduce combiners, partitioners 和 distributed cache ?开发调试MapReduce 应用 ?如何实现MapReduce 应用中的输入/输出 ?常见MapReduce 算法 ?如何用MapReduce 来联结数据集 ?如何把Hadoop 嵌入到企业已有的计算环境里 ?如何使用Hive、Impala 和 Pig 来快速开发数据分析应用 ?如何使用Oozie 来创建管理工作流 培训内容: ?介绍 ?Hadoop 起源和动机 ?Hadoop 基本概念和HDFS ?MapReduce 介绍 ?Hadoop 集群和Hadoop 生态系统 ?使用Java 编写 MapReduce 程序 ?使用Streaming 编写 MapReduce 程序 ?MapReduce 单元测试 ?深入Hadoop API ?开发技巧 ?Reducer 和Partitioner ?数据输入/输出 ?常见MapReduce 算法 ?用MapReduce 来联结数据集 ?把Hadoop 嵌入到企业已有的计算环境里 ?Hive、Impala和 Pig 简介 ?Oozie 简介 ?结论 ?附录:Cloudera Enterprise

招生对象: 课程长度:4天/24小时 培训对象: 已经熟悉 Apache Hadoop的开发员。培训对象应该对 Hadoop 的体系结构和 API 比较熟悉并具备应用开发的经验。Cloudera 的Hadoop开发员和管理员培训可以作为基础课程。 学员基础: 该课程适合于供开发员和系统管理员学习 HBase。具备数据库和数据建模的基础和经验将对本课程的学习有所帮助,但不是必需的。具备 Java 基础和经验将有所帮助。Cloudera 的开发员和管理员培训可以提供学员相关的基础。 培训内容: ?HBase 机群组件 ?何时该使用HBase 以及何时不该使用 HBas ?如何使用HBase shell 来直接操作 HBase 数据 ?如何优化设计 HBase schemas 来进行有效的数据存储和恢复 ?学习使用HBase 的 Java API 及非 Java API ?如何配置HBase 机群 ?如何管理HBase 机群, 发现和解决性能问题 课程大纲: ?介绍 ?Hadoop 介绍 ?HBase 介绍 ?HBase 基本概念 ?HBase 管理API ?HBase 数据访问API(上) ?HBase 数据访问API(中) ?HBase 数据访问API(下) ?HBase 体系结构(上) ?HBase 体系结构(下) ?HBase 安装和配置 (上) ?HBase 安装和配置 (中) ?HBase 安装和配置 (下) ?HBase 里的Row Key 设计 ?HBaseSchema 设计 ?HBase 生态系统介绍 ?结论
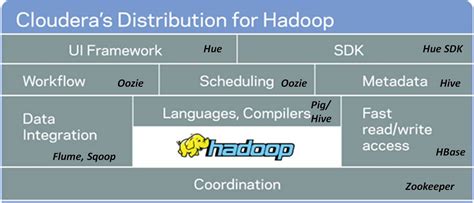
招生对象: 课程长度:3天/18小时 培训对象: 需要使用Hadoop来进行数据分析的数据分析员,商业分析员,开发员以及系统管理员。 学员基础: 建议需具备SQL、简单Unix/Linux命令和脚本编程经验。无需Hadoop基础和经验。 学习内容: ?ApacheHadoop基础及数据ETL(包括数据提取、转换及加载)、如何通过使用Hadoop相关工具将数据载入Hadoop并进行分析处理 ?如何使用ApachePig对多个关联的数据集进行join操作以及如何分析不同的独立数据 ?如何使用ApacheHive:通过定义合适的表来组织数据、执行各种数据变换、简化复杂查询 ?如何使用Impala来对存储在HDFS里的大规模数据进行实时和交互式的分析查询 ?如何根据数据分析任务来选择合适的数据分析工具 学习大纲: ?介绍 ?Hadoop基础 ?Pig基础 ?使用Pig进行简单数据分析 ?使用Pig处理复杂数据 ?使用Pig分析处理多数据集 ?扩展Pig ?Pig排错和优化 ?Hive基础 ?使用Hive进行数据分析 ?Hive数据管理 ?使用Hive分析处理文本数据 ?Hive优化 ?扩展Hive ?Impala基础 ?使用Impala进行数据分析 ?如何选取数据分析工具 ?结论

招生对象: 课程长度:4天/24小时 课程描述: Hadoop、Yarn、Spark是企业构建生产环境下大数据中心的关键技术,也是大数据处理的核心技术,是每个云计算大数据工程师必修课。 大数据时代的精髓技术在于Hadoop、Yarn、Spark,是大数据时代公司和个人必须掌握和使用的核心内容。 Hadoop、Yarn、Spark是Yahoo!、阿里淘宝等公司公认的大数据时代的三大核心技术,是大数据处理的灵魂,是云计算大数据时代的技术命脉之所在,以Hadoop、Yarn、Spark为基石构建起来云计算大数据中心广泛运行于Yahoo!、阿里淘宝、腾讯、百度、Sohu、华为、优酷土豆、亚马逊等公司的生产环境中。 Hadoop、Yarn、Spark三者相辅相成 .Hadoop中的HDFS是大数据时代公认的首选数据存储方式; .Yarn是目前公认的较佳的分布式集群资源管理框架; .Spark是目前公认的大数据统一计算平台; 工业和信息化部电信研究院于2014年5月发布的“大数据白皮书”中指出: “2012 年美国联邦政府就在全球率先推出“大数据行动计划(Big data initiative)”,重点在基础技术研究和公共部门应用上加大投入。在该计划支持下,加州大学伯克利分校开发了完整的大数据开源软件平台“伯克利数据分析软件栈(Berkeley Data Analytics Stack),其中的内存计算软件Spark的性能比Hadoop 提高近百倍,对产业界大数据技术走向产生巨大影响” ----来源:工业和信息化部电信研究院 Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术。目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、Interactive Ad-Hoc Query等方面都有自己的技术,并且是ApacheProject,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。 国外一些大型互联网公司已经部署了Spark。甚至连Hadoop的早期主要贡献者Yahoo现在也在多个项目中部署使用Spark;国内的淘宝、优酷土豆、网易、Baidu、腾讯、皮皮网等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。 刚刚结束的2014 Spark Summit上的信息,Spark已经获得世界20家公司的支持,这些公司中包括Intel、IBM等,同时更重要的是包括了较大的四个Hadoop发行商(Cloudera,Pivotal, MapR, Hortonworks)都提供了对非常强有力的支持Spark的支持,尤其是是Hadoop的头号发行商Cloudera在2014年7月份宣布“Impala’s itfor interactive SQL on Hadoop; everything else will move to Spark”,具体链接信息 http://t.cn/Rvdsukb,而其实在这次SparkSummit之前,整个云计算大数据就已经发声巨变: 1,2014年5月24日Pivotal宣布了会把整个Spark stack包装在Pivotal HD Hadoop发行版里面。这意味这较大的四个Hadoop发行商(Cloudera, Pivotal, MapR,Hortonworks)都提供了对Spark的支持。http://t.cn/RvLF7aM星火燎原的开始; 2,Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark; 3,Cloudera的机器学习框架Oryx的执行引擎也将由Hadoop的MapReduce替换成Spark; 4,Google已经开始将负载从MapReduce转移到Pregel和Dremel上; 5,FaceBook则将原来使用Hadoop的负载转移到Presto上; 现在很多原来使用深度使用Hadoop的公司都在纷纷转向Spark,国内的淘宝是典型的案例,国外的典型是Yahoo!,我们以使用世界上使用Hadoop较典型的公司Yahoo!为例,大家可以从Yahoo!的数据处理的架构图看出Yahoo!内部正在使用Spark: 不得不提的是Spark的“One stack torule them all”的特性,Spark的特点之一就是用一个技术堆栈解决云计算大数据中流处理、图技术、机器学习、交互式查询、误差查询等所有的问题,此时我们只需要一个技术团队通过Spark就可以搞定一切问题,而如果基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题; 伴随Spark技术的普及推广,对专业人才的需求日益增加。Spark专业人才在未来也是炙手可热,作为Spark人员,需要掌握的技能模型如下: 学员基础: 对云计算有强烈的兴趣,能够看懂基本的Java语法。 培训对象: 1.对云计算、分布式数据存储于处理、大数据等感兴趣的朋友 2.传统的数据库,例如Oracle、MaySQL、DB2等的管理人员 3.Java、C等任意一门编程语言的开发者; 4.网站服务器端的开发人员 5.在校大学生、中专生或者刚毕业的学生 6.云计算大数据从业者; 7.熟悉Hadoop生态系统,想了解和学习Hadoop与Spark整合在企业应用实战案例的朋友; 8.系统架构师、系统分析师、高级程序员、资深开发人员; 9.牵涉到大数据处理的数据中心运行、规划、设计负责人; 10.政府机关,金融保险、移动和互联网等大数据来源单位的负责人; 11.高校、科研院所涉及到大数据与分布式数据处理的项目负责人; 12.数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员; 课程目标: 直接上手Hadoop工作,具备直接胜任Hadoop开发工程师的能力;轻松驾驭以Spark为核心的云计算大数据实战技术,从容解决95%以上的云计算大数据业务需求; ?彻底理解Hadoop 代表的云计算实现技术的能力 ?具备开发自己网盘的能力 ?具备修改HDFS具体源码实现的能力 ?从代码的角度剖析MapReduce执行的具体过程并具备开发MapReduce代码的能力 ?具备掌握Hadoop如何把HDFS文件转化为Key-Value让供Map调用的能力 ?具备掌握MapReduce内部运行和实现细节并改造MapReduce的能力 ?掌握Spark的企业级开发的所有核心内容,包括Spark集群的构建,Spark架构设计、Spark内核剖析、Shark、Spark SQL、Spark Streaming、图计 算GraphX、机器学习等; ?掌握Spark和Hadoop协同工作,能够通过Spark和Hadoop轻松应对大数据的业务需求; ?掌握企业线上生产系统中应用Spark /Hadoop成功案例,以及与现有企业BI平台整合的方案; 培训职业目标: ?Hadoop工程师,能够开发的Hadoop分布式应用 ?Hadoop完整项目的分析、开发、部署的全过程的能力 ?Spark高级工程师 ?大数据项目总负责人 ?云计算大数据CTO 培训内容: 时间 内容 天 第1个主题:Hadoop三问(彻底理解Hadoop) 1、 Hadoop为什么是云计算分布式大数据的事实开源标准软件框架? 2、Hadoop的具体是如何工作? 3、Hadoop的生态架构和每个模块具体的功能是什么? 第2个主题:Hadoop集群与管理(具备构建并驾驭Hadoop集群能力) 1、 Hadoop集群的搭建 2、 Hadoop集群的监控 3、 Hadoop集群的管理 4、集群下运行MapReduce程序 第3主题:彻底掌握HDFS(具备开发自己网盘的能力) 1、HDFS体系架构剖析 2、NameNode、DataNode、SecondaryNameNode架构 3、保证NodeName高可靠性较佳实践 4、DataNode中Block划分的原理和具体存储方式 5、修改Namenode、DataNode数据存储位置 6、使用CLI操作HDFS 7、使用Java操作HDFS 第4主题:彻底掌握HDFS(具备修改HDFS具体源码实现的能力) 1、RPC架构剖析 2、源码剖析Hadoop构建于RPC之上 3、源码剖析HDFS的RPC实现 4、源码剖析客户端与与NameNode的RPC通信 第二天 第1个主题:彻底掌握MapReduce(从代码的角度剖析MapReduce执行的具体过程并具备开发MapReduce代码的能力) 1、MapReduce执行的经典步骤 2、wordcount运行过程解析 3、Mapper和Reducer剖析 4、自定义Writable 5、新旧API的区别以及如何使用就API 6、把MapReduce程序打包成Jar包并在命令行运行 第2个主题:彻底掌握MapReduce(具备掌握Hadoop如何把HDFS文件转化为Key-Value让供Map调用的能力) 1、 Hadoop是如何把HDFS文件转化为键值对的? 2、源码剖析Hadoop读取HDFS文件并转化为键值对的过程实现 3、源码剖析转化为键值对后供Map调用的过程实现 第3个主题:彻底掌握MapReduce(具备掌握MapReduce内部运行和实现细节并改造MapReduce的能力) 1、 Hadoop内置计数器及如何自定义计数器 2、 Combiner具体的作用和使用以及其使用的限制条件 3、 Partitioner的使用较佳实践 4、 Hadoop内置的排序算法剖析 5、自定义排序算法 6、 Hadoop内置的分组算法 7、自定义分组算法 8、MapReduce常见场景和算法实现 第4个主题:某知名电商公司Hadoop实施全程揭秘(具备掌握商业级别Hadoop的分析、开发、部署的全过程的能力) 通过电商公司现场案例展示商业级别一个完整项目的分析、开发、部署的全过程 第三天 第1个主题:YARN(具备理解和使用YARN的能力) 1、YARN的设计思想 2、YARN的核心组件 3、YARN的共组过程 4、YARN应用程序编写 第2个主题:ResourceManager深度剖析(具备深刻理解ResourceManager的能力) 1、ResourceManager的架构 2、ClientRMService 与AdminService 3、NodeManager 4、Container 5、 Yarn的 HA机制 第3个主题:NodeManager深度剖析(具备掌握NodeManager及Container的能力) 1、 NodeManager架构 2、 ContainerManagement 3、 Container lifecycle 4、 资源管理与隔离 第4堂课:Spark的架构设计(具备掌握Spark架构的能力) 1.1 Spark生态系统剖析 1.2 Spark的架构设计剖析 1.3 RDD计算流程解析 1.4 Spark的出色容错机制 第四天 第1堂课:深入Spark内核 1 Spark集群 2 任务调度 3 DAGScheduler 4 TaskScheduler 5 Task内部揭秘 第2堂课:SparkSQL 1 Parquet支持 2 DSL 3 SQL on RDD 第3堂课:Spark的机器学习 1 LinearRegression 2 K-Means 3 Collaborative Filtering 第4堂课:Spark的图计算GraphX 1 Table Operators 2 Graph Operators 3 GraphX

招生对象: 课程长度:10天/60小时 培训对象: 企业管理者、CIO、CTO、政府信息部门官员、项目(开发)经理、顾问;IT经理,IT顾问,IT支持专家;系统工程师、数据中心管理员、云计算管理员及想加入云计算队伍的您。 学员基础: 计算机相关专业;具备基本Linux系统管理经验;具备编程经验的开发人员;熟悉Java;不需要事先掌握Hadoop相关知识 课程目标: 通过考试可获得Cloudera Certified Administrator for Apache Hadoop (CCAH) ;Cloudera Certified Developer for Apache Hadoop (CCDH) 证书 培训内容: 主题 内容 Hadoop基础 初识Hadoop及其分布式文件系统 【主要内容】Hadoop是什么,Hadoop可以做什么,Hadoop的分布式文件系统(HDFS)及其特点,HDFS如何承载应用 搭建伪分布式的Hadoop环境 【主要内容】如何利用一台Linux机器搭建你的个Hadoop环境?如何从Hadoop的日志中发现它的故障、异常等 开发你的个MapReduce程序 【主要内容】函式编程与MapReduce,MapReduce程序的主题结构,在Eclipse上搭建MapReduce开发环境,如何运行你的MapReduce程序,用ANT自动化MapReduce程序的部署 在企业内网中快速搭建真正分布式的Hadoop环境 【主要内容】如何在企业内网中快速搭建一个真正的分布式的Hadoop环境?涉及YUM源,部署脚本等。 HIVE基础与实践 【主要内容】HIVE的架构和实现方式,HIVE Metastore的类型和实现方式,HQL语言基础,如何用HIVE做大数据分析等 深入解析HDFS 深度解析HDFS系统配置 【主要内容】HDFS及Linux中与HDFS相关的配置项详解,常用的HDFS必配项及其在实践中的设置方法 玩转HDFS 【主要内容】如何管理和维护HDFS,查找HDFS的基本命令,如何获取帮助,HDFS中的两个较常用命令集——dfs和dfsadmin 深度解析HDFS的五大关键特性 【主要内容】EditLog、Checkpoint、Rebalance、Rack Awareness和Replication 深度解析HDFS的读写过程和性能优化 【主要内容】HDFS在文件读写过程(结合HDFS源代码),HDFS的租约机制与无锁读写特性,如何从操作系统、磁盘、文件系统和网络等几个层面来优化的HDFS性能 Trouble Shooting HDFS 【主要内容】HDFS的常见问题,Namenode的常见问题及其处理方法,元数据损坏时如何恢复,Datanode的常见问题及其处理方法 深入浅出Zookeeper 【主要内容】Paxos与Google的分布式协同机制,Chubby与Zookeeper,Zookeeper的原理、部署方法和应用技巧 Hadoop HA理论与实践 【主要内容】Hadoop HA的前世今生,Hadoop HA中是否存在数据丢失的风险,Hadoop2中的两种HA方式——QJM和NFS,QJM方案配置演示 HDFS RAID与HttpFS 案例分析:制作基于HDFS的对象存储 深入解析MapReduce 深度刨析JobTracker和TaskTracker 【主要内容】JobTracker和TaskTracker的工作原理详解 MapReduce经典案例刨析与开发思想 【主要内容】函式编程的回顾与深化,MapReduce典型程序分析:Wordcount、Top-k与Join 定制你的MapReduce 【主要内容】Inputformat、OutputFormat和Partitioner等 让MapReduce程序飞速运行(一) 【主要内容】深度解析Split、Sort、Shuffling、Merge四大MapReducce程序执行过程中所经历的四大关键过程,如何利用这4大过程来优化MapReduce程序 让MapReduce程序飞速运行(二) 【主要内容】Combiner原理及其在MapReduce中的作用,MapReduce实际案例分析 MapReduce程序开发的高级技巧 【主要内容】用Python等第三方语言快速编写MapReduce程序、自动串接多个Mapper和Reducer、容忍一定程度的失败任务和错误记录等 进一步玩转MapReduce的平台级优化 【主要内容】MapReduce程序的主要性能瓶颈及各种“坑”,MapReduce的主要性能配置项及其配置方法 YARN和MRv2选讲 案例分析:挖掘运营商中的大数据

招生对象: 课程长度:3天 培训对象: 需要使用Apache Spark来开发功能强大的数据分析应用的程序开发人员和大数据工程师。 学员基础: 本课程使用Scala和Python进行讲解。学员需至少掌握这两种编程语言的其中一种,具备面向对象的编程基础及经验。掌握基本的Linux技能,无需Hadoop方面的基础和经验。 培训内容: ?使用Spark的动机 ?Spark基础 ?Resilient Distributed Datasets (RDDs) ?HDFS ?在机群环境下运行Spark ?Spark并发处理 ?Caching和Persistence ?编写Spark应用 ?集成Spark、Hadoop到企业数据中心 ?Spark Streaming ?常用Spark算法举例 ?Spark性能 教学大纲: ?介绍 ?传统大规模系统的问题 ?Spark简介 ?Spark Shell ?RDDs ?Spark函数式编程 ?RDD操作 ?键-值对型RDD ?MapReduce和键-值对型RDD操作 ?HDFS体系结构 ?如何使用HDFS ?Spark机群 ?Spark机群Web UI ?RDD分区和HDFS数据本地化 ?使用分区并行处理 ?RDD Lineage ?Caching和Persistence ?编写Spark应用 ?创建SparkContex ?配置Spark属性 ?生成和运行Spark应用程序 ?日志 ?Spark和Hadoop生态系统 ?Spark和MapReduce ?Spark流处理 ?Streaming单词计数举例 ?Streaming操作 ?滑动窗口Streaming操作 ?编写Spark流处理应用 ?迭代算法 ?图处理分析 ?机器学习 ?共享变量:Broadcast变量 ?共享变量:Accumulators ?常见性能问题
 沪ICP备18048269号-1
沪ICP备18048269号-1  电子营业执照
电子营业执照
 教育
教育
 全国教育网站
全国教育网站
 企业信用等级AA级
企业信用等级AA级