中科院计算所培训中心
7x24小时咨询热线
Severity: Warning
Message: preg_match(): No ending delimiter '^' found
Filename: controllers/School.php
Line Number: 699
Backtrace:
File: /data/web/collect_web/application/controllers/School.php
Line: 699
Function: preg_match
File: /data/web/collect_web/application/controllers/School.php
Line: 15
Function: get_real_ip
File: /data/web/collect_web/index.php
Line: 315
Function: require_once
7x24小时咨询热线
 |
 |
 |
 |
 |
 |
 |
 |
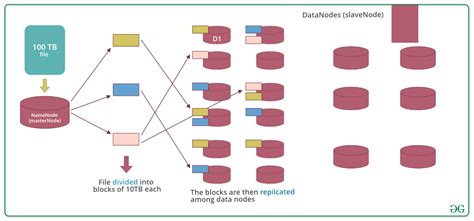
招生对象: 关于举办“大数据分布式存储系统”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 “分布式存储”主要指的是通过网络将多个节点的存储能力/存储资源整合在一起,构成一个统一整体的数据存储方式、技术和系统。存储系统当前正处于前所未有的变革时期,一方面,大数据的发展对于数据存储的需求与日俱增;另一方面,传统存储厂商的出货量却增长并不明显,甚至有下滑的倾向。这其中很大的因素就是分布式存储逐步受到用户的青睐,这和分布式存储的特点是相关的,在大数据时代,很多企业的数据都是逐步积累的,这就要求存储系统有很好的横向扩展能力;而要对传统存储设备进行横向扩展,会带来很高的成本,但是分布式存储却能够比较好的解决这样的问题。正是基于目前的发展,培训中心特举办“大数据分布式存储系统”,具体安排如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到数据存储的数据中心运行、规划、设计负责人或主要技术人员。 3,政府机关,金融保险、移动和互联网等单位的负责人或主要技术人员。 4,高校、科研院所牵涉到大数据存储的项目负责人或主要技术人员。 二、师资 由业界知名分式存储专家亲自授课: 李老师 OStorage创始人,国内知名开源布道师 曾在中科院担任专项课题组负责人,在船舶、航天、国防等领域国家大型工程项目中负责私有云和大数据系统的设计与实施,开展分布式系统相关的科研工作并培养研究生。 2015年以来,致力于以独立于厂商的态度进行云计算、云存储等技术的研究和推广,曾为中国电信、中国一汽、HP、爱立信等多家央企和跨国公司提供技术和培训,并被华为聘为顾问专家。曾赴日本东京、美国奥斯汀国际技术会议上发表演讲。 2016年4月在美国举办的OpenStack峰会中,李老师关于分布式存储与云存储的课程入选,面向来自美国和世界各地的学员授课。 三、培训内容 1. 分布式存储系统概述 1.1 分布式系统的概念 1.2 存储系统的技术基础 1.3 大数据存储的需求以及传统存储架构的瓶颈 1.4 分布式系统的硬件和软件 2. 大数据集(超大文件)存储 2.1 GFS与HDFS的由来与相互关系 2.2 大数据集存储需求分析 2.3 GFS/HDFS的架构剖析 2.4 GFS/HDFS的可靠性保障机制 2.5 GFS/HDFS如何支持高并发 2.6 GFS/HDFS如何支持扩展 2.7 GFS/HDFS与MapReduce的结合 2.8 案例分析 3. 海量小文件存储 3.1 GFS/HDFS在海量小文件存储中遇到的问题 3.2 淘宝和京东的解决方案 3.3 一致性哈希的原理与应用 3.4 OpenStack Swift的特点 3.5 OpenStack Swift架构剖析 3.6 OpenStack Swift的一致性模型与CAP原理 3.7 OpenStack Swift的存储策略功能 3.8 案例分析 4. 分布式存储技术发展新动向和趋势 4.1 HDFS对小文件存储的优化 4.2 Swift对大文件存储和MapReduce的支持 4.3 Linux基金会Kinetic Open Storage项目 4.4 计算存储融合架构与分布式块存储 4.5 统一存储的优势、问题与选型 四、培训时间、地点 时间: 2016年8月19日-8月20日 地点:北京 五、证 书 培训结束,颁发中科院计算所职业培训中心“大数据分布式存储系统”培训结业证书。 六、费 用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。

招生对象: 关于举办“大数据分析挖掘-基于Hadoop/Mahout/MLlib的大数据挖掘”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 随着互联网、移动互联网和物联网的发展,我们已经切实地迎来了一个大数据的时代。大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的需求。目前对大数据的分析工具,首选的是Hadoop/Yarn平台。Hadoop/Yarn在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台。为解决广大系统设计人员深入研究与开发大数据技术的需要,培训中心特在“大数据处理技术-基于Hadoop/Yarn的实战”课程的基础上,针对已有或即将建立Hadoop/Yarn集群,拥有海量数据,需要做用户推荐、产品聚类,信息分类等大数据分析用户,举办“大数据分析挖掘-基于Hadoop/Mahout/MLlib的大数据挖掘”培训班,具体事宜通知如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到大数据处理的数据中心运行、规划、设计负责人。 3,政府机关,金融保险、移动和互联网等大数据来源单位的负责人。 4,高校、科研院所牵涉到大数据与分布式数据处理的项目负责人。 二、学员基础 1,对IT系统设计有一定的理论与实践经验。 2,数据仓库与数据挖掘处理有一定的基础知识。 3,对Hadoop/Yarn/Spark大数据技术有一定的了解。 三、师资 由业界知名大数据专家亲自授课: 杨老师 主要研究网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,主持和参与了多个国家和省部级基金项目,具有丰富的工程实践及软件研发经验。 四、培训要点 互联网点击数据、传感数据、日志文件、具有丰富地理空间信息的移动数据和涉及网络的各类评论,成为了海量信息的多种形式。当数据以成百上千TB不断增长的时候,我们在内部交易系统的历史信息之外,需要一种基于大数据分析的决策模型和技术支持。 大数据通常具有:数据体量(Volume)巨大,数据类型(Variety)繁多,价值(Value)密度低,处理速度(Velocity)快等四大特征。如何有效管理和高效处理这些大数据已成为当前亟待解决的问题。大数据处理意味着更严峻的挑战,更好地管理和处理这些数据也将会获得意想不到的收获。 Google发布的GFS和MapReduce等高可扩展、高性能的分布式大数据处理框架,证明了在处理海量网页数据时该框架的优越性。在此基础上,Apache Hadoop开源项目开发团队,克隆并推出了Hadoop/Yarn系统。该系统已受到学术界和工业界的广泛认可和采纳,并孵化出众多子项目(如Hive,Zookeeper和Mahout等),日益形成一个易部署、易开发、功能齐全、性能优良的系统。在此基础上,以Berkley牵头设计的Spark/BDAS技术,实现了内存级别的分布式处理模式,使用户无需关注复杂的内部工作机制,无需具备丰富的分布式系统知识及开发经验,即可实现大规模分布式系统的部署与大数据的并行处理。 本课程从大数据挖掘分析技术实战的角度,结合理论和实践,全方位地介绍Mahout和 MLlib等大数据挖掘工具的开发技巧。本课程涉及的主题包括:大数据挖掘及其背景,Mahout和 MLlib大数据挖掘工具,推荐系统及电影推荐案例,分类技术及聚类分析,以及与流挖掘和Docker技术的结合,分析了大数据挖掘前景分析。 本课程教学过程中还提供了案例分析来帮助学员了解如何用Mahout和 MLlib挖掘工具来解决具体的问题,并介绍了从大数据中挖掘出有价值的信息的关键。 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论Mahout和 MLlib解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,希望推动大数据分析挖掘项目开发上升到一个新水平。 五、培训内容 讲大数据挖掘及其背景 1)数据挖掘定义 2)Hadoop相关技术 3)大数据挖掘知识点 第二讲 MapReduce/DAG计算模式 1)分布式文件系统DFS 2)MapReduce计算模型介绍 3)使用MR进行算法设计 4)DAG及其算法设计 第三讲 云挖掘工具Mahout/MLib 1)Hadoop中的Mahoutb介绍 2)Spark中的Mahout/MLib介绍 3)推荐系统及其Mahout实现方法 4)信息聚类及其MLlib实现方法 5)分类技术在Mahout/MLib中的实现方法 第四讲 推荐系统及其应用开发 1)一个推荐系统的模型 2)基于内容的推荐 3)协同过滤 4)基于Mahout的电影推荐案例 第五讲 分类技术及其应用 1)分类的定义 2)分类主要算法 3)Mahout分类过程 4)评估指标以及评测 5)贝叶斯算法新闻分类实例 第六讲 聚类技术及其应用 1)聚类的定义 2)聚类的主要算法 3)K-Means、Canopy及其应用示例 4)Fuzzy K-Means、Dirichlet及其应用示例 5)基于MLlib的新闻聚类实例 第七讲 关联规则和相似项发现 1)购物篮模型 2)Apriori算法 3)抄袭文档发现 4)近邻搜索的应用 第八讲 流数据挖掘相关技术 1)流数据挖掘及分析 2)Storm和流数据处理模型 3)流处理中的数据抽样 4)流过滤和Bloom filter 第九讲 云环境下大数据挖掘应用 1)与Hadoop/Yarn集群应用的协作 2)与Docker等其它云工具配合 3)大数据挖掘行业应用展望 六、培训目标 1, 全面了解大数据处理技术的相关知识。 2,学习Hadoop/Yarn/Spark的核心数据分析技术 3,深入学习Mahout/MLlib挖掘工具在大数据中的使用。 4,掌握Storm流处理技术和Docker等技术与大数据挖掘结合的方法。 七、培训时间、地点 时间: 2016年8月3日-8月5日 地点:北京 2016年8月22日-8月24日 地点:上海 八、证书 培训结束,颁发中科院计算所职业培训中心“大数据分析挖掘-基于Hadoop/Mahout/MLlib的大数据挖掘”结业证书。 九、费用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。

招生对象: 关于举办“R数据挖掘技术-基于R语言的数据挖掘和统计分析技术”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 随着互联网、移动互联网和物联网的发展,我们已经切实地迎来了一个大数据的时代。如何对海量数据进行挖掘和分析,已经成为一个非常重要且紧迫的需求。 R是一个数据分析和图形显示的程序设计环境,用于统计分析、绘图的语言和操作。是目前广大企业较通用的数据挖掘与统计分析工具。为解决广大系统设计人员深入进行数据挖掘与统计分析需要,培训中心特举办“R数据挖掘技术-基于R语言的数据挖掘和统计分析技术”培训班,具体事宜通知如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到数据挖掘和统计分析的数据中心运行、规划、设计负责人。 3,政府机关,金融保险、移动和互联网等大数据来源单位的负责人。 4,高校、科研院所牵涉到数据挖掘与统计分析处理的项目负责人。 二、学员基础 1,对IT系统设计有一定的理论与实践经验。 2,对数据挖掘和数据处理方法有一定的基础知识。 3,对Hadoop/Spark等大数据技术有一定的了解。 三、师资 由业界知名大数据专家亲自授课: 杨老师 主要研究网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,主持和参与了多个国家和省部级基金项目,具有丰富的工程实践及软件研发经验。 四、培训要点 互联网点击数据、传感数据、日志文件、具有丰富地理空间信息的移动数据和涉及网络的各类评论,成为了海量信息的多种形式。当数据以成百上千TB不断增长的时候,我们在内部交易系统的历史信息之外,需要一种基于大数据分析的决策模型和技术支持。 目前对大数据的分析工具,有Hadoop/Yarn上基于Java语言的Mahout,有Spark上基于Scala的MLlib,但这些工具都由于比较年轻以及侧重于计算背景的分布式,与传统的行业应用还不是太紧密,在传统行业中应用,至少目前效果和影响还有待提高。 R语言是一个数据分析和图形显示的程序设计环境,广泛用于统计分析、绘图的语言和操作。同时R也是一个用于统计计算和统计制图的优秀工具,也是GNU的一个自由、免费、源代码开放的软件。R包括一套完整的数据处理、计算和制图软件系统。其功能包括:数据存储和处理系统;数组运算工具(其向量、矩阵运算方面功能尤其强大);完整连贯的统计分析工具;优秀的统计制图功能;简便而强大的编程语言:可操纵数据的输入和输入,可实现分支、循环,用户可自定义功能。 事实上,R是目前广大企业通用的数据挖掘与统计分析工具,为此Spark等大数据平台从2014年就开始在SparkR等技术中,将R引入到大数据统计分析中,未来形成以R语言为代表的SparkR, 以类SQL为代表的SparkQL,以及Hive on Tez三足鼎立的大数据统计分析工具和平台。 本课程从R语言数据挖掘和统计分析实战的角度,结合理论和实践,全方位地介绍R这一高性能数据分析工具的开发技巧。本课程涉及的主题包括:本培训将介绍基于R语言进行数据处理、数据探索的基本方法,利用R语言实现模型选择、Logistic回归及决策树算法,以及贝叶斯算法及支持向量机、神经网络等算法原理及实现进行讲解。本课程教学过程中还从国内外经典R语言教材和应用中,提取了大量的案例分析来帮助学员了解如何用R系列工具来解决数据统计分析的具体问题,并介绍了从数据中挖掘出有价值的信息的关键。 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,希望推动R相关的项目开发上升到一个新水平。 五、培训内容 讲数据挖掘和R简介 1.1 数据挖掘 1.2 R语言 1.3 Iris数据集 1.4Bodyfat数据集 第二讲数据的导入与导出 2.1 R数据的保存与加载 2.2 CSV文件的导入与导出 2.3 通过ODBC从数据库中读取数据 2.4 从Excel中导入与导出数据 第三讲数据可视化展现 3.1 查看数据 3.2 单个变量展现 3.3 多个变量展现 3.4 更多探索 3.5 将图表保存到文件中 第四讲决策树与随机森林 4.1 使用party包构建决策树 4.2 使用rpart包构建决策树 4.3 随机森林 第五讲回归分析 5.1 线性回归 5.2 逻辑回归 5.3 广义线性回归 5.4 非线性回归 第六讲聚类分析 6.1 k-means聚类 6.2 k-medoids聚类 6.3 层次聚类 6.4 基于密度的聚类 第七讲离群点检测 7.1 单变量的离群点检测 7.2 局部离群点因子检测 7.3 用聚类方法进行离群点检测 7.4 时间序列数据的离群点检测 第八讲时间序列分析 8.1 R中的时间序列数据 8.2 时间序列分解 8.3 时间序列预测 8.4 时间序列聚类 8.5 时间序列分类 第九讲关联规则 9.1 关联规则的基本概念 9.2 Titanic数据集 9.3 关联规则挖掘 9.4 消除冗余 9.5 解释规则 9.6 关联规则的可视化 第十讲社交网络分析 10.1 词项网络 10.2 推文网络 10.3 双模式网络 第十一讲 R与Hadoop/Spark等大数据技术的融合 1)R/Hadoop数据处理技术介绍 2)SparkR数据处理技术介绍 3)基于Hadoop/Yarn集群的应用展望 六、培训目标 1,全面了解R语言数据挖掘的相关知识。 2,学习R的数据挖掘核心技术方法以及应用特征。 3,深入使用R在数据挖掘和分析中的使用。 4,了解R与Hadoop、Spark等技术的融合使用。 七、培训时间、地点 时间: 2016年8月10日-8月12日 地点:北京 八、证 书 培训结束,颁发中科院计算所职业培训中心“R数据挖掘技术-基于R语言的数据挖掘和统计分析技术”结业证书。 九、费 用 培训费:5500元/人(含教材、证书、午餐、学习用具)食宿统一安排,费用自理。

招生对象: 关于举办“云计算与大数据处理技术”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 云计算提供了一种对资源“按需索取服务”的能力,确保了使用时间与需要时间的完全一致,从而建立了一种分布式、高效率、低成本的IT商业模式。正是这些特点,使云计算成为IT发展的潮流与趋势。为解决广大系统设计人员深入研究与开发云计算系统的需要,培训中心特举办“云计算与大数据处理技术”培训班,具体事宜通知如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到海量数据处理的机构数据中心运行、规划、设计负责人。 3,云服务运营服务提供商规划负责人。 4,高校、科研院所牵涉到大数据与分布式数据处理的项目负责人。 二、学员基础 1,对IT系统设计有一定的理论与实践经验。 2,数据仓库与大数据处理有一定的基础知识。 三、师资 由业界知名云计算专家亲自授课: 杨老师 主要研究网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,主持和参与了多个国家和省部级基金项目,具有丰富的工程实践及软件研发经验。 雷老师 国内知名企业云平台技术负责人,中国云亲身实践者。 四、培训要点 今天,随着IT规模越来越大,数据规模呈几何级数增长,已经超出了传统技术方法所能解决的范畴。为此,人们把目光转向了刚刚兴起的云计算,希望通过云计算来实施海量数据处理解决方案,实现以更小的成本来处理更大规模数据的目标,并成为目前云计算应用所面对的极大挑战。本课程基本思想如下: 1,目前,“云计算”已经不是一个刚刚流行的时髦概念了,在一些传统IT方法显得无能为力的场合,云计算正在开始大展拳脚,表现了强大的解决问题的能力,海量数据存储与处理正是属于这种场合。我们如何在云计算分布式环境下正确设计大数据量数据模型?如何在设计中解决资源、效率、安全性、可靠性等一系列极难平衡的问题?如何通过云计算帮助我们解决在传统IT技术中看似解决不了的敏感问题?这些都是我们在云计算架构设计中需要深入研究的键问题。 2,理解问题的方法是分析成功案例,本课程分别从多个角度分析在面对海量数据处理的困难时,不同的应用体系是如何解决问题并获得成功的。研究这些已有的体系不是目的,而是希望学员能够通过学习这些解决问题的方法和思路,通过归纳整理深入理解,再根据自己所面对的领域特征,形成解决具体实际问题的方案。这也是让云计算在海量数据处理领域真正发挥作用的有效途径。 3,云计算是一种服务,在云计算应用架构设计中,就必须考虑作为服务与普通的产品设计有哪些不同?需要考虑的产品的服务特征有哪些?如何搭建面向不同层次、合适的服务平台?在这个过程中,我们需要考虑哪些问题?有哪些成功的案例?有些什么解决方案? 4,云计算应用最重要的问题是安全问题。安全不是一个后期需要解决的独立问题,而是在前期就需要投入巨大精力来考虑的产品策略。可以说,安全性与可用性是云计算能否顺利实施与应用的关键点,也是云计算架构设计的关键因素。我们应该如何考虑安全问题?如何解决诸如数据安全、网络安全、主机安全、数据管理以及灾难恢复等一系列问题?如何制定合适的安全性与可用性策略?在实践中有什么经验和教训? 5,为了把传统数据中心改造为基于云计算的服务系统,虚拟化是一个重要手段。我们必须深入研究虚拟化技术是如何实现的。虚拟化技术有哪几个层面的问题?如何正确应用虚拟化技术来实现把基础设施向服务转型?各种虚拟化技术有些什么优点?有哪些陷阱?如何规划技术解决方案?如何正确进行云计算体系结构设计? 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,希望推动国内云计算项目开发上升到一个新水平。 五、培训内容 讲 云计算的概念与现状 1)云计算的概念 2)云计算发展现状 3)云计算实现机制 4)云计算的发展环境 5)云计算的优势 第二讲 从Google云计算体系,理解海量数据处理的方法 1)如何构建海量存储文件系统? GFS系统架构 GFS容错机制 GFS系统管理技术 MapReduce产生背景 MapReduce编程模型 MapReduce实现机制 MapReduce案例分析 2)如何提供锁服务解决分布式数据一致性问题? Chubby的设计思路 Chubby中的Paxos算法 Chubby文件系统 3)如何建立规模庞大的高性能表结构? BigTable设计目标 BigTable系统架构 BigTable服务器 BigTable性能优化 4)如何建立高可用性和高可扩展性的数据系统? Megastore设计目标 Megastore数据模型 Megastore事务及并发控制 Megastore基本架构 Dapper监控系统 Dapper关键性技术 Dapper工具 第三讲 从Hadoop云计算项目,进一步研究云数据处理方法 1)HDFS:高可靠性处理机制及应用 Hadoop项目简介 HDFS体系结构 HDFS关键运行机制 Hadoop vs Google Hadoop API Hadoop环境搭建 2)HBASE:庞大、极其稀疏的可扩展性数据模型 Hbase简介 HBase的运行机制 HBase与 HDFS HBase的对外接口 ZooKeeper的数据模型 ZooKeeper的读写机制 ZooKeeper的使用方法 第四讲 从Windows Azure,理解平台即服务的本质 1)微软云计算平台 2)微软云操作系统Windows Azure 3)微软云关系数据库SQL Azure 4)Azure AppFabric 5)Azure Marketplace 第五讲 从Amazon云计算,讨论如何提供云服务 1)Dynamo基础存储架构 2)弹性计算云EC2 3)简单存储服务S3 4)简单队列服务SQS 5)简单数据库服务Simple DB 6)关系数据库服务RDS 7)内容推送服务CloudFront 第六讲 实施云计算的关键点:安全策略 1)云计算安全是一个必须前期重视的策略 2)云计算的特征与安全挑战 3)云计算的安全体系与关键技术 4)基础架构云安全框架 5)云计算安全平台 第七讲 当前数据中心如何向云计算环境转变? 1)VMware云产品 2)云管理平台 vCenter 3)vCloud Service Director 4)VMware的网络和存储虚拟化 5)主流商业云计算解决方案比较 6)主流开源云计算系统比较 7)国内代表性云计算平台比较 第八讲 基础设施即服务(IaaS)关键实现技术 1)IaaS技术体系概述 2)服务器虚拟化技术 CPU虚拟化 内存虚拟化 I/O虚拟化 3)存储虚拟化技术 存储系统概述 存储设备层的存储虚拟化 块聚合层的存储虚拟化 文件/记录层的存储虚拟化 4)主机网络虚拟化 第九讲 软件即服务(SaaS)关键实现技术 1)SaaS技术概述 2)呈现层技术综述 3)调度层技术 基于DNS的调度 基于虚拟IP的调度 基于链路聚合的调度 基于应用的调度 调度策略 4)业务层 5)数据层 6)用户管理和配置管理 7)用户体验的设计 8)课程总结 六、培训目标 1,深入理解通过云计算实现海量数据处理的思想、方法与实践。 2,理解安全性和可用性设计的问题、方法与实践。 3,掌握把传统数据中心改造成云计算中心的技术与方法。 4,掌握虚拟化技术的核心技术方法以及应用特征。 七、培训时间、地点 时间: 2016年7月28日-7月30日 地点:北京 八、证 书 培训结束,颁发中科院计算所职业培训中心“云计算与大数据处理技术”结业证书。 九、费 用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。
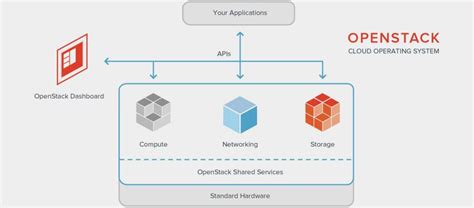
招生对象: 培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。2,牵涉到云计算与大数据处理的数据中心运行、规划、设计负责人或主要技术人员。3,政府机关,金融保险、移动和互联网等云计算来源单位的负责人或主要技术人员。4,高校、科研院所牵涉到云计算与大数据处理的项目负责人或主要技术人员。 学员基础 1,对IT系统设计有一定的理论与实践经验。2,有一定的IT软硬件基础知识。 师资 李老师 中国科学院专项课题组组长。IEEE云计算与信号处理国际研讨会发起人,IEEE云计算学报等多个国际期刊审稿人。在高水平国际会议和SCI期刊上发表论文十多篇,并拥有多项专利。带领团队完成多个云计算方面的工程项目,在船舶、航天等领域多个国家大型工程项目中负责私有云和大数据系统的设计与实施,为互联网公司提供相关的培训、和系统优化。目前主要研发方向为分布式对象存储、大数据系统云化。 培训要点 在国家信息技术新一轮发展战略中,以云计算和大数据为代表的创新方法成为发展的重点。经历了喊口号、布局深耕之后,云计算应用开始显现出巨大的商业价值,触角已延伸到与信息化相关的各行各业,取得了不菲的成果。在经历了多年的发展之后,云计算技术已经发生了翻天覆地的变化。 使用公共服务产品只是云计算应用的一个方面,特别是在公有云和私有云并存的混合云时代,人们已经不满足于仅仅使用已有的云服务,而是希望对传统的数据中心进行改造,以充分发挥现有资源的价值。在这个背景下,我们就需要培养千千万万对云计算有深刻理解、有高超技术能力的技术团队和技术人员,从而做好准备,以应对即将到来的IT技术大变革。 在云计算的技术方法中,OpenStack占据着显著重要的位置,它使云计算技术不仅仅是个虚拟化系统,而是发展成了一种云操作系统和管理平台,并且引领云计算进入3.0的新时代。OpenStack对大数据云化、存储服务化以及软件生态环境,提供了重要的技术支持,引发了整个IT技术架构的革命性变化。在应用OpenStack云计算框架的时候,人们的困惑在于: 1,OpenStack的架构思想到底是什么? 2,OpenStack是如何影响云计算生态环境的? 3,如何进行云计算身份认证与服务目录的部署和管理? 4,如何进行存储服务的部署和管理? 5,如何进行计算资源的部署和管理? 6,如何进行网络服务的部署和管理? 7,如何进行企业信息系统的云化? 本课程希望解决这些问题,课程的特点就是落地:以OpenStack开源框架作为背景,以理论知识引领实际操作,在一个实际环境下,自主搭建、配置和管理云平台。这样就可以保证,在四天的课程中,既包括理论阐述,也包括实际动手操作,从而达到理论与实际相结合,为企业培养云计算技术骨干力量的目的。 培训内容 讲 OpenStack概述 1. 云计算、虚拟化及OpenStack的产生与发展 2. 云的层次与部署模式 3. OpenStack的企业级应用举例 4. 不仅仅是IaaS(基础设施即服务)——OpenStack是什么? 第二讲 云的硬件基础 1. 基于通用硬件构建云基础设施和采用商用设备的比较 2. OCP项目和天蝎计划 3. 融合、超融合基础设施 4. 软件定义网络和软件定义存储 第三讲 OpenStack的操作 1. 初识OpenStack的图形界面和命令行 2. 虚拟机和卷的创建与管理 3. 租户私有网络及路由器的创建和管理 4. 浮动IP、元数据和密钥注入 5. OpenStack的API 6. 通过Heat Template批量创建资源 第二天 第四讲 OpenStack的架构 1. 组成OpenStack的项目 2. OpenStack逻辑架构 3. OpenStack核心项目的内部组成 4. OpenStack的部署架构 第五讲 OpenStack的身份认证与服务目录——Keystone 1. OpenStack的身份认证机制详解 2. WSGI框架与Keystone的配置 3. 生产中Keystone可能出现的问题、常见的优化方案与取舍 第六讲 OpenStack的存储服务(一)——Glance与Cinder 1. 虚机镜像存储Glance 2. 镜像存储在生产中的常见问题及优化 3. 块存储服务(卷服务、云硬盘)Cinder 4. 块存储服务后端的常见实现方式及比较 第三天 第七讲 OpenStack的存储服务(二)——对象存储Swift 1. 两类典型的大数据存储问题:大文件存储和海量小文件存储 2. 分布式存储技术的演进、对象存储的概念及技术特点 3. Swift逻辑架构和部署架构 4. Swift的企业级应用 5. Swift在生产种常见的性能问题及优化 6. 以太网硬盘、Linux基金会KOSP项目及应用 第八讲 OpenStack的计算资源管理——Nova 1. 虚拟机的原理与两种典型的Hypervisor的架构 2. Nova对Hypervisor的管理 3. OpenStack创建一个虚拟机的工作流程 4. Nova的资源调度及主要配置选项 第四天 第九讲 OpenStack的网络服务——Neutron 1. 虚机联网的原理、Nova-network及其问题 2. SDN与NFV技术 3. Neutron的功能及架构 4. Neutron管理下的虚机网络流量 5. 存在问题及发展方向 第十讲 再谈企业信息系统的云化 1. 云化不等同于虚拟化 2. 传统的应用架构和性能检测手段在云上遇到的问题 3. 什么是Cloud Native 4. 基于OpenStack的应用云化案例 第十一讲 OpenStack的进阶话题 1. 自动化部署 2. OpenStack与大数据 3. 案例介绍,Q&A (各讲均包含实际操作环节) 培训目标 1,全面了解OpenStack的架构与思想2,掌握OpenStack的部署和管理方法3,了解企业信息系统云化的方法论 培训时间、地点 时间:2016-05-18 到 2016-05-21 地点:北京 证 书 培训结束,颁发中科院计算所职业培训中心“OpenStack部署和管理”培训结业证书 费 用 培训费:7200元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理

招生对象: 关于举办“云计算技术的最新进展与实践”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 云计算提供了一种对资源“按需索取服务”的能力,确保了使用时间与需要时间的完全一致,从而建立了一种分布式、高效率、低成本的IT商业模式。正是这些特点,使云计算成为IT发展的潮流与趋势。为解决广大系统设计人员深入研究与开发云计算系统的需要,培训中心特举办“云计算技术的最新进展与实践”培训班,具体事宜通知如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到云计算与大数据处理的数据中心运行、规划、设计负责人。 3,政府机关,金融保险、移动和互联网等云计算来源单位的负责人。 4,高校、科研院所牵涉到云计算与大数据处理的项目负责人。 二、学员基础 1,对IT系统设计有一定的理论与实践经验。 2,有一定的IT软硬件基础知识。 三、师资 由业界知名云计算专家亲自授课: 李老师 中国科学院专项课题组组长。IEEE云计算与信号处理国际研讨会发起人,IEEE云计算学报等多个国际期刊审稿人。在高水平国际会议和SCI期刊上发表论文十多篇,并拥有多项专利。带领团队完成多个云计算方面的工程项目,在船舶、航天等领域多个国家大型工程项目中负责私有云和大数据系统的设计与实施,为互联网公司提供相关的培训、和系统优化。目前主要研发方向为分布式对象存储、大数据系统云化。 四、培训要点 在国家信息技术新一轮发展战略中,以云计算和大数据为代表的创新方法成为发展的重点。云计算经历了多年的发展之后,已经发生了翻天覆地的变化,并进入了云计算3.0时代。 一个显著的变化在于,云计算技术不再仅仅是个虚拟化系统,而是发展成了一种云操作系统和管理平台,这种变化对于大数据云化、存储服务化、软件定义以及软件的生态环境,提供了重要的技术支持,继而引发了整个IT技术架构的革命性变化。在这个不断变化和发展的云环境中,很多问题都在困惑着需要创新思维的系统设计人员,包括: 1,云计算目前的发展状态是什么? 2,如何选择云计算的开源项目? 3,云计算硬件和网络技术的特点是什么? 4,如何建立和应用云存储? 5,如何基于云计算建立新型信息系统? 6,如何基于开源软件搭建云上的大数据系统? 7,基于云计算的信息系统有哪些成功的经验? 本课程着力于解决这些问题,并希望由此带给学员全新的视野和崭新的设计理念。 五、培训内容 天 讲 云计算技术现状概述 1)云计算的产生与发展 2)云计算的层次与部署模式 3)虚拟化技术和软件定义的计算、存储和网络 4)基于云的企业级信息系统架构 5)传统 IT 架构往云上的迁移以及异构集成 第二讲 云计算相关的开源项目 1)开源虚拟化技术的比较 2)OpenStack 的产生、发展与生态圈 3)OpenStack 架构剖析 4)Docker 概述 第三讲 云基础设施的硬件基础 1)基于通用硬件构建云基础设施和采用商用设备的比较 2)系统托管模式 3)OCP项目和天蝎计划 4)超融系统的优点及其应用 第四讲 云计算中的网络技术 1)传统网络架构和管理模式在云时代遇到的问题 2)软件定义网络(SDN) 3)网络功能虚拟化(NFV) 4)SDN和NFV相关的开源项目 第二天 第五讲 云存储 1)大数据和互联网应用中新的存储问题 2)对象存储和云存储 3)几种典型开源分布式存储的比较 4)存储的空间效率问题和高密度存储技术 第六讲 再谈信息系统的云化 1)云化不等同于虚拟化 2)云化的特点——非持久性的计算资源、Auto-Scaling与Elastic、通过云的API实现Orchestration 3)云应用的性能监控 4)云应用与微服务架构 5)传统IT向云端迁移的案例 第七讲 大数据系统和云计算的关系 1)大数据系统的技术特点 2)大数据系统云化的特殊需求 3)大数据和云的结合案例 4)基于开源软件搭建云上的大数据系统 第八讲 案例分析 1)传统行业案例分析 2)互联网行业案例分析 六、培训目标 1,全面了解云计算目前的发展状态 2,学习选择云计算开源项目的方法 3,理解云计算硬件和网络技术的特点 4,理解建立和应用云存储的方法 5,掌握如何基于云计算建立新型信息系统 6,学习如何基于开源软件搭建云上的大数据系统 七、培训时间、地点 时间: 2016年1月22日-1月23日 地点:北京 八、证 书 培训结束,颁发中科院计算所职业培训中心“云计算技术纵览”培训结业证书。 九、费 用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。 附件: “云计算技术的最新进展与实践”培训回执 单 位 (盖章) 地 址 邮编 网 址 传真 人 email 学员代表 手机 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 注:1. 此表复印有效。 2. 请参加学习人员尽早发送回执,我们将提前为您安排培训期间事宜。谢谢!

招生对象: 关于举办“数据仓库与数据挖掘(结合SPSS和WEKA案例)”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力。迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 随着近年来数据资源的日益丰富,从数据资源提取信息和知识进行辅助决策非常必要。如何从企业内部众多的信息系统中提取真正反映企业运营状况的有效信息资源、深入挖掘价值客户信息,从而提高经营管理决策的支撑能力和快速响应能力,以期对纷繁变化的市场和竞争对手有足够的洞察力、掌控力和预判力,成为企业下一阶段信息系统建设的目标和方向。而这一目标正是要靠IT领域中的数据仓库和商务智能技术来实现和达到。 本次培训重在突出数据仓库与数据挖掘决策支持的本质,介绍数据挖掘的各种方法、技术实现手段,通过对实例的深入剖析解释它们的原理。 一、培训对象 数据仓库管理人员、建模人员,分析人员和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员。 二、师资 杨老师:中科院计算所培训中心高级讲师,主要研究方向为网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,具有丰富的工程实践及软件研发经验。 三、培训内容 1、数据仓库原理及联机分析技术介绍 Ø 数据仓库结构体系,数据仓库数据模型 Ø 数据抽取、转换和装载,元数据管理 Ø OLAP概念及其数据模型 Ø 多维数据的显示 2、数据仓库设计与开发 Ø 数据仓库分析与设计 Ø 数据仓库开发过程 Ø 数据仓库技术与开发的困难 Ø OLAP的多维数据分析 3、基于数据仓库的决策支持系统 Ø 基于数据仓库的查询与报表 Ø 多维分析与原因分析 Ø 实时决策与预测未来 Ø 自动决策及其应用介绍 4、数据仓库案例剖析 Ø 移动运营商的客户投诉联机分析,基于Business Intelligence Dev Studio Ø 通过对客户投诉详单,设计相应的投诉模型,建立其相应的维度,事实表等 Ø 通过对客户投诉进行分类,发现其中的共同点以及差异,方便制定相应计划 Ø 积极的应对客户投诉,对客户投诉进行监控,及时对可能导致的客户进行挽留 Ø 某公司数据仓库决策支持系统 Ø 统计业数据仓库系统 Ø 沃尔玛数据仓库系统 5、数据挖掘与知识发现 Ø 数据挖掘的任务与对象 Ø 数据挖掘方法 Ø 数据挖掘相关技术 6、关联分析算法及其案例 Ø 关联规则的分类 Ø Aprior算法详解 Ø 从频繁项集产生关联规则 Ø 基于Climentine的购物篮实例分析- 7、聚类分析算法及其案例 Ø 聚类分析的概念 Ø 主要的聚类方法 Ø K-means算法详解 Ø 基于Climentine的用户数据聚类实例- 8、其它数据挖掘算法介绍 Ø 决策树算法 l ID3算法 l 由决策树提取分类规则 l 基于Climentine的决策树分析实例 Ø 神经网络算法 l 神经网络的概念 l 网络拓扑及其算法 l 基于Climentine的神经网络分析实例 四、培训时间、地点 时间:2016年7月6日-7月8日 地点:北京 五、证书 培训结束,颁发中科院计算所职业培训中心“数据仓库与数据挖掘”结业证书。 六、费用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。

招生对象: 关于举办“大数据分析- 基于Hadoop/Mahout的大数据挖掘”培训的通知 各有关单位: 中国科学院计算技术研究所是国家专门的计算技术研究机构,同时也是中国信息化建设的重要支撑单位,中科院计算所培训中心是致力于高端IT类人才培养及企业内训的专业培训机构。中心凭借科学院的强大师资力量,在总结多年大型软件开发和组织经验的基础上,自主研发出一整套课程体系,其目的是希望能够切实帮助中国软件企业培养高级软件技术人才,提升整体研发能力,迄今为止已先后为国家培养了数万名计算机专业人员,并先后为数千家大型国内外企业进行过专门的定制培训服务。 随着互联网、移动互联网和物联网的发展,我们已经切实地迎来了一个大数据的时代。大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的需求。目前对大数据的分析工具,首选的是Hadoop平台。Hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台。为解决广大系统设计人员深入研究与开发大数据技术的需要,培训中心特在“大数据处理技术-基于Hadoop的实战”课程的基础上,针对已有或即将建立Hadoop集群,拥有海量数据,需要做用户推荐、产品聚类、信息分类等大数据分析用户,举办“大数据分析- 基于Hadoop/Mahout的大数据挖掘(含Spark和Storm应用介绍)”培训班,具体事宜通知如下: 一、培训对象 1,系统架构师、系统分析师、高级程序员、资深开发人员。 2,牵涉到大数据处理的数据中心运行、规划、设计负责人。 3,政府机关,金融保险、移动和互联网等大数据来源单位的负责人。 4,高校、科研院所牵涉到大数据与分布式数据处理的项目负责人。 二、学员基础 1,对IT系统设计有一定的理论与实践经验。 2,有一定的数据仓库与大数据处理的基础知识。 3,有一定的Hadoop技术的基础知识。 三、师资 由业界知名大数据专家亲自授课: 杨老师 主要研究网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,主持和参与了多个国家和省部级基金项目,具有丰富的工程实践及软件研发经验。 四、培训要点 互联网点击数据、传感数据、日志文件、具有丰富地理空间信息的移动数据和涉及网络的各类评论,成为了海量信息的多种形式。当数据以成百上千TB不断增长的时候,我们在内部交易系统的历史信息之外,需要一种基于大数据分析的决策模型和技术支持。 大数据通常具有:数据体量(Volume)巨大,数据类型(Variety)繁多,价值(Value)密度低,处理速度(Velocity)快等四大特征。如何有效管理和高效处理这些大数据已成为当前亟待解决的问题。大数据处理意味着更严峻的挑战,更好地管理和处理这些数据也将会获得意想不到的收获。 Google发布的GFS和MapReduce等高可扩展、高性能的分布式大数据处理框架,证明了在处理海量网页数据时该框架的优越性。GFS/MapReduce框架实现了更高应用层次的抽象,使用户无需关注复杂的内部工作机制,无需具备丰富的分布式系统知识及开发经验,即可实现大规模分布式系统的部署与大数据的并行处理。 Apache Hadoop开源项目开发团队。他们克隆了GFS/MapReduce框架,推出了Hadoop系统。该系统已受到学术界和工业界的广泛认可和采纳,并孵化出众多子项目(如Pig,Zookeeper和Hive等),日益形成一个易部署、易开发、功能齐全、性能优良的系统。 本课程从大数据技术以及Hadoop实战的角度,结合理论和实践,全方位地介绍Hadoop以及Mahout大数据挖掘工具的开发技巧。涉及的主题包括:大数据挖掘及其背景, Hadoop及Mahout大数据挖掘工具,推荐系统及电影推荐案例,分类技术及聚类分析,流挖掘及其它挖掘技术,大数据挖掘前景分析。 教学过程中贯穿了案例分析来帮助学员了解如何用Hadoop和Mahout挖掘工具来解决具体的问题,在关键点上搭建实验环境进行实践研究,以加深对于这些解决方案的理解。并介绍了从大数据中挖掘出有价值的信息的关键。 五、培训内容 讲大数据挖掘及其背景 1)数据挖掘定义 2)Hadoop相关技术 3)大数据挖掘知识点 第二讲 MapReduce计算模式 1)分布式文件系统 2)MapReduce 3)使用MR的算法设计 第三讲 Hadoop中的云挖掘工具Mahout 1)Mahout介绍 2)推荐系统 3)信息聚类 4)分类技术 5)其它挖掘 第四讲 推荐系统及其应用开发 1)一个推荐系统的模型 2)基于内容的推荐 3)协同过滤 4)电影推荐案例 第五讲 分类技术及其应用 1)分类的定义 2)分类主要算法 3)Mahout分类过程 4)评估指标以及评测 5)贝叶斯算法新闻分类实例 第六讲 聚类技术及其应用 1)聚类的定义 2)聚类的主要算法 3)K-Means、Canopy及其应用示例 4)Fuzzy K-Means、Dirichlet及其应用示例 5)路透新闻聚类实例 第七讲 关联规则和相似项发现 1)购物篮模型 2)Apriori算法 3)抄袭文档发现 4)近邻搜索的应用 第八讲 流数据挖掘相关技术 1)流数据挖掘及分析 2)流数据模型 3)数据抽样 4)流过滤 第九讲 大数据挖掘应用前景 1)与Hadoop集群应用的协作 2)与RHadoop等其它云挖掘工具配合 3)大数据挖掘行业应用展望 六、培训目标 1, 全面了解大数据处理技术的相关知识。 2,学习Hadoop的核心技术方法以及应用特征。 3,深入使用Mahout挖掘工具在大数据中的使用。 4,掌握流数据挖掘和其它大数据挖掘关键技术。 七、培训时间、地点 时间: 2016年3月16日-3月18日 地点:北京 八、证书 培训结束,颁发中科院计算所职业培训中心“大数据分析- 基于Hadoop/Mahout的大数据挖掘”结业证书。 九、费用 培训费:5500元/人(含教材、证书、午餐、学习用具等)。住宿协助安排,费用自理。 附件: “大数据分析- 基于Hadoop/Mahout的大数据挖掘”培训回执 单 位 (盖章) 地 址 邮编 网 址 传真 人 email 学员代表 手机 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 学员姓名(注明性别) 注:1. 此表复印有效。 2. 请参加学习人员尽早发送此回执,我们将提前安排培训期间事宜。谢谢!
中科院计算所培训中心 中科院计算所培训中心,成立于1987年,是计算所根据国家普及计算机知识,计算机专业培训而创建的。培训中心依托中国科学院强大的技术背景,历经二十年的发展,为全国各企事业单位、部队、院校等累计培养了近十七万人次的IT精英人才,并为多家企业提供了高质量的服务,现已形成企业内训、高端公开课、GJB5000A/CMMI培训与、企业全方位服务四大业务模块,在业界具有良好信誉。“科学、高效、权威、品质”是北京市海淀区中科院计算所职业技能培训学校的经营宗旨,面向企业人是其[详情]
|

杨老师 教师团队
北京大学计算机研究所助理研究员,博士 博士,男,1970年3月生,1997年7月博士毕业于北京大学计算机系。曾经任职于北京大学计算机研究所助理研究员,美国朗讯公司贝尔实验室研究员。主要研究方向为网络信息分析以及云计算相关技术,长期从事通信网管系统、网络信息处理、商务智能(BI)以及电信决策支持系统的研究开发工作,包括网络中信息的采集、处理、优化及知识发现,具有丰富的工程实践及软件研发经验。主讲:大数据处理技术-基于Hadoop的实战、云计算与大数据处理技术、数据仓库与数据挖掘、Andriod开发技术近期课程:大数据处理技术-基于Hadoop的实战、云计算与大数据处理技术、数据仓库与数据挖掘主持和参与了多个国家和省部级基金项目,负责完成了多项电信网络应用技术研发项目。近年来,在国内外重要学术期刊和国际会议上,发表了研究论文六十余篇,其中被SCI/EI/ISTP引用35篇。曾获得第二、三届中国PC软件大赛优秀奖,北京市科技新星,四川省科技进步二等奖一项,成都市科技进步二等奖、三等奖各一项。目前是IEEE、中国计算机学会、中国通信学会、中国自动化学会、北京市通信学会高级会员。主要的研究工作经历如下:1998-2000任职于美国朗讯公司贝尔实验室(Bell Labs)研究员(MTS)期间,参与“通信网管和决策分析系统”(ActiView项目)的研究开发;2001-2002任教于北京邮电大学电信工程学院期间,和美国蓬天信息技术有限公司合作,主持开发了“北京移动移动客户价值分析系统”。2002-2003和京云万峰技术有限公司合作,参与开发了“国家统计局元数据标准及原型系统”的设计与开发。2004-2005和北京普天首信通信公司合作,参与开发了“普天首信CDMA 2000 1X BSS OMC网络管理系统”,主持其中的网络数据分析模块。2005-2007和北京直真节点公司合作,参与开发“北京移动IP网管系统一期系统”和“二期系统”,主持其中的KPI监控分析模块。2005-2008获得北京市科委科技新星基金支持,主持“电信网络业务性能监控模型研究”项目(项目号2005B41),开发一个基于业务的电信网络性能自适应监控模型,确保电信网络数据业务的安全。2009-2011和日本NTT公司合作,所主持开发的“客户行为模式选择”和“基于Web的问卷系统”,并已在日本NTT投入使用运行。2011-2012主要研究兴趣是针对云环境下的大数据分析,利用Hadoop中的数据分析工具,对河北移动等单位的数据业务进行分析,挖掘分析和发现其中的用户使用行为。从2006年起,长期为广东移动等单位开设讲授《数据仓库与数据挖掘》等课程。目前毕业的数十位研究生已经在Teradata和中国移动等单位负责数据仓库的建设工作。

饶老师 教师团队
北京研究院高级工程师,博士 主讲:云计算与大数据处理技术 近期课程: 中国电信股份有限公司北京研究院高级工程师,博士,云计算与大数据产品线技术和解决方案负责人,从08年开始研究云计算,《云计算解码》编者,先后参与中国电信云计算战略规划,中国电信云计算现网试验,对虚拟化、云计算、大数据、软件定义等技术有深入的研究与理解。

谢老师 教师团队
高级系统架构师 主讲:高级系统架构师、高级软件需求分析师、高级项目管理师、IT战略规划与企业架构、GJB5000A深入理解与实现、提升软件人员职业素养、近期课程:高级系统架构师、高级软件需求分析师、高级项目管理师、IT战略规划与企业架构、GJB5000A深入理解与实现曾主持和参与开发多个大型军用/民用项目,其中“海军导弹抗干扰系统”获科技成果奖(第二获奖人),“石油化工仿真系统”在中国石化系统获得了广泛应用。熟悉各种语言的软件开发方法,分别担任过程序员、项目经理、首席架构师以及机构领导职务。2000年以后,开始致力于提升国内软件企业工程化进程的咨询和培训工作,2002年进入中科院计算所培训中心,先后任课题组主任、教学研发主任,2005年至今任培训中心副校长职务。谢老师多年从事软件工程项目以及教学研究,尤其在软件工程系统架构和需求分析领域,曾作为首席架构师完成大型军用项目并获科技成果奖,作为首席设计师完成石油化工仿真系统,谢老师精通设计与实现,在高速公路管理系统、地铁信息化平台、大型网站、金融信息化、商用软件设计、钢铁信息化等领域担任多家公司顾问,指导开发过程管理、分析和架构设计。谢老师多年来为企业高端人员讲授的“高级系统架构师”、“高级需求分析师”、“高级项目管理师”以及“IT战略规划与企业架构”等课程,在国内软件企业、军队指挥机构、航空船舶设计研发单位以及金融、保险、证券等行业中有相当大的影响。

刘老师 教师团队
科技有限公司执行技术总监 主讲:VC-MFC程序设计精讲、C++技术精讲、matlab课程、虚拟化技术、数据挖掘近期课程:VC-MFC程序设计精讲、C++技术精讲擅长C/C++语言、Symbian/WinCE嵌入式开发、MMO实时服务器构建等。精通面向对象程序开发,项目开发、管理经验丰富。丰富的数据库程序、网络程序开发经验以及跨平台开发与移植经验。主要开发经历:参与国家专利局专利审查辅助系统研发工作,担任子系统项目负责人。此项目采用传统的星型数据库结构与WebService结合的方式,主要工作负责用户需求管理,关键模块设计与实现。累计实现代码8万行左右。联想研究院北研所参与智能手机《烽火台三期》项目,手机平台采用Linux智能操作系统,使用跨平台多重开发环境。具体负责中国联通VOIP网关联通工作,期间对通讯技术、网络开发培养了丰富经验。聚力信通(北京)科技有限公司执行技术总监,参与公司产品战略制定,并先后主持研发了《手机商务助理》、《手机管家》和《移动学生手机平台》等移动互联网应用产品。所有产品的实现均覆盖了Symbian、Windows Mobile,J2ME,MTK平台。期间,对移动互联网技术进行了全面的积累。授课特点:生动幽默,内容追求技术的最新进展,思路清晰,表述准确。生动幽默,内容追求技术的最新进展,思路清晰,表述准确。

余老师 教师团队
Java语言核心技术老师 主讲:“Java语言核心技术”、“SSH框架技术”、“J2SE应用开发技术”、“J2EE Web开发技术”等课程近期课程:“Java语言核心技术”、“SSH框架技术”、“J2SE应用开发技术”、“J2EE Web开发技术”基于java平台的Open Source软件的研发与应用开发,10年以上开发经验,5年以上授课经验,可应用目前主流的轻量级开源开发框架Struts/Struts2/Spring/Hibernate/iBatis等,以及基于JavaEE标准的EJB解决方案,定制完成满足企业级需求的管理软件;现正在项目中利用SOA解决方案满足较高复杂度ERP项目需求。讲课的特点是理论联系实际,内容追求技术的最新进展,思路清晰,表述准确,解答学员的问题耐心。

姜老师 教师团队
国家863项目(国家数字油田)专家,首席架构师 主讲:高质量软件设计、敏捷落地之旅、软件重构与设计模式、设计匠艺近期课程:敏捷落地之旅国家863项目(国家数字油田)专家,首席架构师敏捷中国团队持有人;2005年IBM开发者大会讲师、讲义获得者;国家质量认证中心技术顾问;总参某部技术顾问;国家安全局技术顾问;人民银行技术顾问;大庆油田技术顾问;胜利油田技术顾问;鲁能集团技术顾问;2007年度开源项目之一AgileUML的主架设计师。更重要的是他是一位快乐的实用主义软件工程专家。虽然他热衷于软件开发技术与敏捷开发实践。但是能真正吸引他的是程序与使用者交流和沟通的能力。Jobs是实用开发的“永久消费者”,几乎在任何地方,都可以找到软件开发哲学的灵感。
 沪ICP备18048269号-1
沪ICP备18048269号-1  电子营业执照
电子营业执照
 教育
教育
 全国教育网站
全国教育网站
 企业信用等级AA级
企业信用等级AA级